
# 大模型训练
# 数据准备
数据通常分为通用数据,如网页、书籍、对话;以及专业数据,如多语言数据、科学文本(学术论文)、代码等等
# 数据清洗
为保证大模型使用高质量语料训练,通常需要质量过滤,包括冗余去除、隐私消除、词元切分等步骤
# 数据选取、划分
# Scaling Law
对于计算量,模型参数量,和数据集大小,当不受其他两个因素制约时,模型性能与每个因素都呈现幂律关系,且随着每个因素的量增大,对模型的效果提升越有限。目前已经有研究证明,模型参数量上升时,数据量也需要等比例上升。
# 数据选取方法
- Data Mixing Laws:通过在小规模数据和模型上进行实验,利用训练步数、模型大小和数据混合比例的缩放定律(Scaling Laws),来预测在大规模数据和大型模型上的性能
- DoGE/LESS:重点学习对整体梯度贡献较大的领域,可以使用影响函数来量化每条训练数据对模型的影响。但通常在大模型上直接计算影响函数是困难的,因此可以先知识蒸馏,在小模型上用影响函数分析什么样的数据是关键的
- REGMIX:使用多种数据配比训练一组小型模型,并拟合一个回归模型来预测给定各自配比的模型的性能
# 训练过程
# Pre-train
预训练阶段是通过大规模无监督学习来训练模型,让模型能够从海量的文本数据中学习语言的基本模式、语义和结构。通过学习大量文本,模型掌握语言的句法、词法,甚至潜在的语义关联。通常,预训练需要大量的数据和计算资源来处理巨大的参数量。模型在没有标注数据的情况下学习,需要高质量的数据清洗和设计合适的任务来让模型能够充分理解语言。
# SFT (Supervised Fine-Tuning)
在这个阶段,预训练好的模型会通过特定的任务和标注数据进行微调。这个步骤的目的是让模型在预训练的基础上,针对具体应用场景(如分类、问答、翻译等)进行适应性优化。
相比完全从头训练一个新模型,微调在时间和计算资源上更加经济高效。但有可能出现过拟合以及灾难性遗忘,即微调后的模型可能在特定领域表现良好,但在其他领域的表现可能会下降。
# RLHF
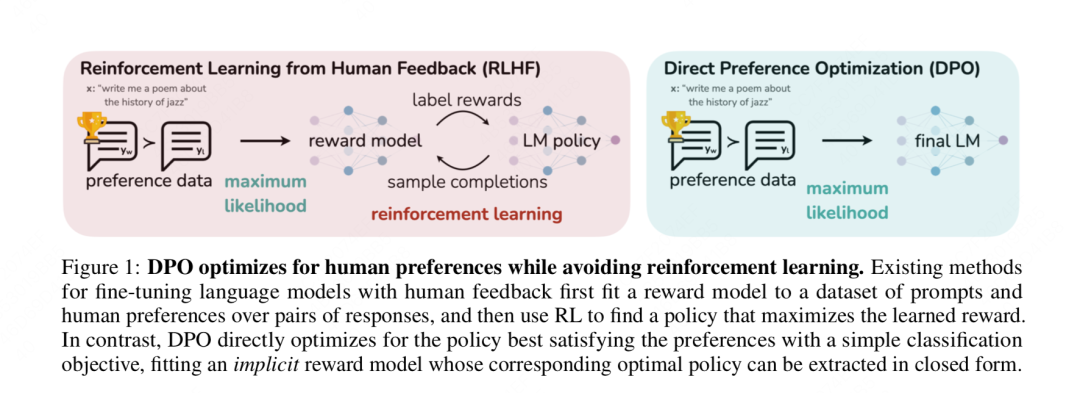
在LLM对齐问题上,OpenAI提出的RLHF训练范式最为人熟知,同时也是ChatGPT行之有效的对齐方案。
RLHF通常包含三个步骤:SFT, Reward Model, PPO, 该方案优点不需多说,缺点也很明显:训练流程繁琐、算法复杂、超参数多和计算量大,因此RLHF替代方案层出不穷。
# PPO (Proximal Policy Optimization)
PPO 是一种在线强化学习方法,的核心是训练一个能更好刻画人类偏好的 Reward Model,然后使用这个 Reward Model 来显性评估模型生成结果的好坏,最终指导模型的微调。
PPO 主要缺点是需要训练单独的 Reward Model,其成本高昂并且需要大量额外数据。而 Reward Model 的好坏也直接影响了最终模型的效果。模型也有可能仅仅去学习如何讨好强化学习模型,而没有真正理解答案间的语义差距。
# DPO (Direct Preference Optimization)
DPO 是一种离线强化学习方法,无需显性构建 Reward Model,而是直接根据偏好数据来优化策略。它巧妙地绕过了构建奖励模型和强化学习这两个的繁琐过程,直接通过偏好数据进行微调,效果简单粗暴,在使模型输出更符合人类偏好的同时,极大地缩短了训练时间和难度。
然而,四川大学的 Duanyu Feng 最近的研究《Towards Analyzing and Understanding the Limitations of DPO: A Theoretical Perspective》表明:DPO 损失函数降低产生人类不喜欢的 response 的概率的速度比增加产生人类偏好的 response 的概率的速度更快,这导致:
- DPO 阻碍了 LLM 产生人类偏好的 response 的学习能力
- DPO 对 SFT 的有效性很敏感
# 两者的优势与不足
PPO 和 DPO 作为 LLMs Alignment 的主流算法有其各自的优势。PPO 训练一个单独的 Reward Model 来预测人类偏好。然后使用这个 Reward Model 来微调 LLMs。DPO 使用 KL constraint 直接导出最优策略,无需单独的 Reward Model。简化了 LLMs 训练流程,计算效率更高。DPO 在计算、速度和工程工作方面更加高效,但在模型效果上 PPO 要优于 DPO。在实际应用中可以根据具体需求进行选择。
# 微调技术
# Adapter tuning
Adapter tuning通过在预训练模型的每一层中插入一个小的适配器模块来实现微调。这些适配器模块包含少量可训练参数,它们在微调过程中被更新,而原始模型的参数保持不变。适配器通常由两个线性层组成,中间可能有一个非线性激活函数。
假设原始模型的第层的输出为,则经过适配器后的输出可以表示为: 其中,是非线性激活函数,是降维层的权重和偏置,和是升维层的权重和偏置。
假设我们有一个预训练的BERT模型,我们想要对其进行适配器微调以适应一个新的文本分类任务。我们会在BERT的每一层后添加适配器模块,并只训练这些模块的参数,而不改变BERT的原始参数。
# Prompt tuning
Prompt tuning是一种利用自然语言提示(prompt)来引导预训练语言模型的方法。这种方法不需要修改模型的内部参数,而是通过设计合适的提示来激发模型对特定任务的理解和执行。
假设我们要使用GPT-3进行问答任务,我们可以设计一个提示:“请回答以下问题:”,然后将这个问题作为输入的一部分,连同原始问题一起输入到GPT-3中。
# Prefix tuning
Prefix tuning是Prompt tuning的一种变体,它在输入序列的前面添加一组可学习的虚拟token作为前缀。这些虚拟token在训练过程中被优化,以更好地引导模型的输出。
假设我们要对一个生成模型进行微调,以便它能够生成特定风格的文本。我们可以添加一个可学习的前缀,这个前缀在训练过程中被优化,以使模型生成符合特定风格的文本。
# P-tuning
P-tuning是一种将Prompt转换为可学习的Embedding的方法。它使用一个小型的神经网络来生成Prompt的Embedding,然后将这些Embedding与输入数据一起送入预训练模型。
假设我们要使用BERT进行情感分析任务,我们可以设计一个提示,并通过一个小的神经网络将其转换为Embedding,然后将这个Embedding与文本输入一起送入BERT。
# Freeze tuning
Freeze tuning是指在微调过程中冻结模型的大部分参数,只训练模型的一小部分参数,通常是最后一层或者特定的几层。
# LoRA
LoRA(Low-Rank Adaptation)是一种通过低秩矩阵分解来微调模型的方法。它通过添加一对低秩矩阵来近似参数更新,从而减少需要训练的参数数量。
假设原始参数矩阵为,LoRA通过添加低秩矩阵和来近似参数更新:,其中,和是低秩矩阵,它们的乘积近似于参数更新。
LoRA通常在Self-attention层调整参数,并且可以应用各种低精度技术。
# QLoRA
QLoRA(Quantized LoRA)是LoRA的一个变体,它结合了量化技术来进一步减少模型的大小和提高微调效率。QLoRA在微调过程中使用量化技术来减少模型参数的位数,从而减少内存占用和计算需求。
QLoRA的公式与LoRA相似,但是在参数更新时会应用量化操作:,其中,表示量化操作。
# Tokenizer
# Byte-Pair Encoding(BPE)
BPE是一种无监督的分词技术,它从字符级别开始,逐步合并最常见的字符对,以形成更大的词汇单元。这个过程是迭代的,每次迭代都会根据新的词汇表重新计算字符对的频率,并合并最频繁出现的字符对。
假设有一个简单的语料库:"I like apples, I like oranges.",初始词汇表只包含单个字符。BPE的步骤如下:
- 初始化词汇表:{'I', ' ', 'l', 'i', 'k', 'e', 'a', 'p', 'p', 'l', 'e', 's', ',', 'o', 'r', 'a', 'n', 'g', '.'}
- 统计字符对频率:'I like' 出现两次,'like ' 出现两次,等等。
- 合并最频繁的字符对:'like' 和 ' '(空格)合并为 'like_'。
- 更新词汇表:{'I', 'like_', 'apples,', 'oranges.'}
- 重复步骤2-4,直到达到所需的词汇表大小或满足其他停止条件。
最终,词汇表可能包含像 'like_', 'apples,', 'oranges.' 这样的词汇单元,以及原始的字符。
# WordPiece
WordPiece是一种基于BPE的分词方法,它通过合并字符或子词来优化语言模型的困惑度。WordPiece的目标是创建一个能够最大化句子概率的词汇表。
继续使用上面的例子,WordPiece可能会合并 'like' 和 ' '(空格)为 'like_',然后继续寻找其他可以合并的子词,以提高整个语料库的概率。
# SentencePiece
SentencePiece是一个开源工具,它提供了多种分词方法,包括BPE和Unigram。SentencePiece的特点是可以处理任何语言,包括那些没有空格分隔的语言,如中文。
# Unigram
Unigram是一种基于概率的分词方法,它通过最大化整个语料库的似然概率来构建词汇表。Unigram模型在每次迭代中尝试合并词汇表中的项,并选择能够提高语料库概率的合并
# BPE的优势
- 更好的处理未知词汇
- 更小的词汇表
- 更好的捕捉词缀和词形变化
- 跨语言的通用性
# 训练损失函数
# BERT
- MLM (Masked Language Model):在MLM任务中掩盖部分词汇,并通过最大化掩盖词汇的预测概率来进行训练,假设是被掩盖的词语集合,是模型在上下文下预测词汇的概率,那么MLM损失为
- NSP (Next Sentence Prediction):NSP任务用于预测两句话是否连续,假设表示标签,是模型预测两句和是否连续的概率,那么NSP损失函数可以表示为:$
# GPT
GPT 使用 自回归语言模型 (Autoregressive Language Model) 的损失函数。其目标是根据前面的词预测下一个词。模型根据已知的词来最大化预测下一个词的出现概率。