
# Text Graph
In the Natural language processing field, text graph or textual graph is a form of data model representing textual information and semantic relationship. It models the structure and semantics of text by representing words, phrases, or sentences as nodes in the graph, and using edges to represent their association relationships.
Text graphs can capture various relationships within a text, such as co-occurrence relationships between words, similarity between sentences, correlations between concepts, contextual relationships, synonymous relationships, superlative relationships, etc. By analyzing and modeling these relationships in text, text graphs can provide more comprehensive semantic information and richer contextual understanding. This method is commonly used for text NLU, text classification, text summarization, relationship extraction, text implication tasks, etc.
The definition of nodes and edges in text graphs is very broad. For nodes, they can be considered as individual words or sentences, domain specific terms, or entities mentioned in the text (which in this case devolves into relationship diagrams). For edges, they can be co-occurrence relationships, contextual relationships, subordinate relationships, and so on.
Using textual graphs offers several benefits:
- Capturing Semantic Associations: Textual graphs can capture semantic relationships within text, including associations between words, relevance between phrases, and similarity between sentences. By modeling these semantic relationships, textual graphs provide more comprehensive semantic information, aiding models in better understanding the meaning of text.
- Enhancing Contextual Understanding: Textual graphs can establish connections within the context of sentences or paragraphs, linking related information through edge associations. This helps models better comprehend information within the context, capturing relationships between contexts and improving the accurate understanding of the text.
- Integrating Multimodal Information: Textual graphs can be combined with information from other modalities such as images and audio, forming multimodal graphs. This integration is particularly useful when dealing with multimodal data, enabling a better representation and modeling of relationships between text and other modalities, achieving a more comprehensive understanding of information.
- Semantic Inference and Knowledge Extraction: Through textual graphs, semantic inference and knowledge extraction can be performed. For example, by analyzing relationships within the textual graph, one can engage in inference and deduction, uncovering hidden semantic relationships. Furthermore, textual graphs can extract essential concepts and key information from text, which can be utilized for knowledge representation and the construction of knowledge graphs.
# TextGCN
Paper title: TextGCN:Graph Convolutional Networks for Text Classification
This paper constructs a text graph based on the co-occurrence relationship of the text and uses one-hot encoding as the initial feature. The paper applies GCN to text classification tasks, constructs a network model TextGCN, and conducts experimental verification on four long text datasets (20NG, R8, R52, Ohsumed) and one short text dataset (MR, movie short comment dataset).
- Firstly, the paper constructs a large heterogeneous text graph network that includes word nodes and document nodes, so that global co-occurrence words can be clearly constructed.

The number of nodes in the text graph network is the number of document nodes (the size of the dataset) plus the number of non repeating words contained in the dataset (the size of the vocabulary), as shown in the following figure.
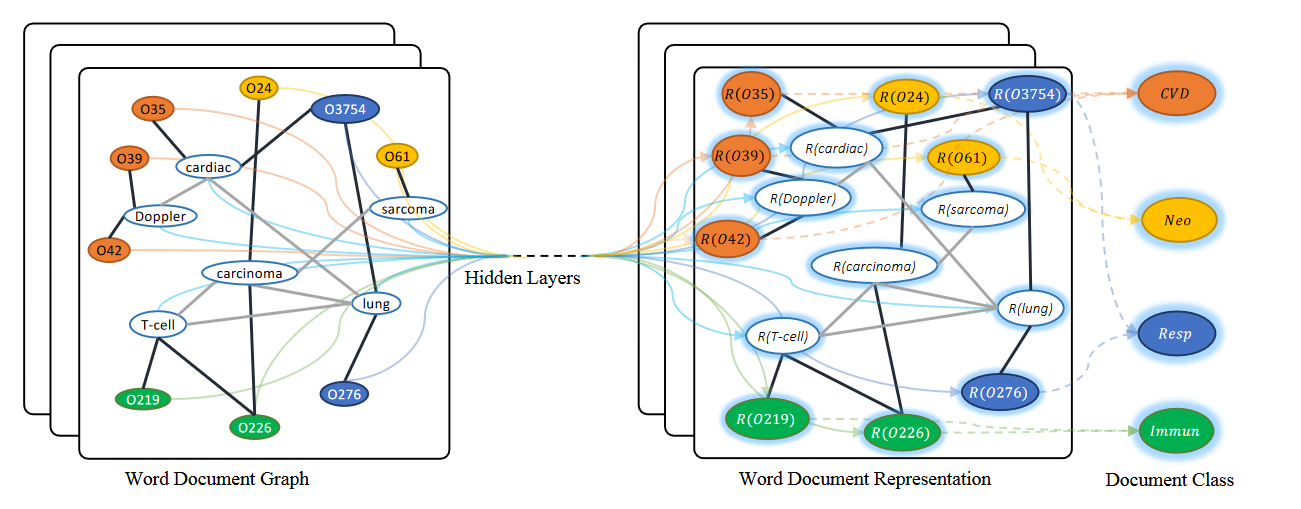
Afterwards, this paper made modifications on the basis of GCN, mainly proposing to construct a graph using the entire corpus. The nodes in the graph represent each document in the corpus and all words in the dictionary, and construct a large graph represented by an adjacency matrix. After constructing the graph and its adjacency matrix, use GCN for transfer calculations.
Finally, this paper uses a two-layer GCN for model training and proves through experiments that the two-layer GCN performs better than single-layer or more than two-layer GCNs. Finally, the author conducted experimental comparisons on the selection of network parameters in this paper, and visualized the word vector learning of the model, demonstrating the effectiveness of GCN in document classification in multiple aspects. This indicates that graphs and their adjacency matrices in GCN can be constructed in various ways, such as the degree of correlation between words, the degree of correlation between words and documents, and even dependency trees. Therefore, proposing new graph construction methods is also an innovation in GCN's document classification.
# BertGCN
Paper title: BertGCN: Transductive Text Classification by Combining GCN and BERT
BertGCN is also a two part Build Graph and Model Train.
Composition: The Build Graph section is the same as TextGCN, so I skipped it without any difference. Let's focus on the model section.
Initialization: BertGCN does not use a random initialization strategy when initializing node embeddings, but instead uses Bert to process document nodes for initialization, while Word nodes are directly initialized to 0 for initial embeddings.
Results and model training obtained by integrating BERT module and GCN module
In the section of integrating Bert and GCN training, it is pointed out in this paper that embedding the Bert encoder into GCN and directly combining training will result in two problems,
During gradient feedback, the Bert part cannot achieve effective gradient optimization.
GCN is a fully updated graph. Assuming that the graph has 10k document nodes, then the BERT part with 10k documents simultaneously undergoes BERT ENCODER to obtain document embedding, which is then thrown into the GCN layer for update training. This is obviously not achievable.
In response to these issues, this paper proposes an interpolation update method. The final interpolation update is to add up the two document embeddings obtained from GCN and Bert separately acting on the text to obtain the fusion classification probability Z, and then use the cross entropy loss function to make a classification prediction.
Due to the existence of BERT, BertGCN can only load one batch at a time during training, rather than the entire graph. To address this issue, BertGCN used Memory Bank.
It saved the features of all document nodes and separated the graph nodes from each batch during training. Each batch only needs to extract a small portion of the required node features from them.
Simply put, the memory storage mechanism dynamically updates a small number of document nodes through each iteration, and uses these nodes to train the model. This avoids reading all features into BERT for calculation at once, greatly reducing memory overhead.
However, one issue that arises from this is that due to the fact that document nodes are updated in batches, there may be inconsistencies in the features input into the model at different iterations of an Epoch. Therefore, BertGCN adopts a smaller learning rate when updating the BERT module to reduce inconsistencies between features. To accelerate training, BertGCN initializes the BERT module in BertGCN with a BERT model trained on a downstream dataset before training.