
# Transformer in Graph
This paper presents Graphormer, a novel graph neural network (GNN) architecture that builds upon the standard Transformer model to excel in graph representation learning tasks. The authors address the challenge of adapting the Transformer, which is primarily designed for sequential data, to effectively model graph-structured data. They propose several structural encoding methods to incorporate graph-specific information into the model:
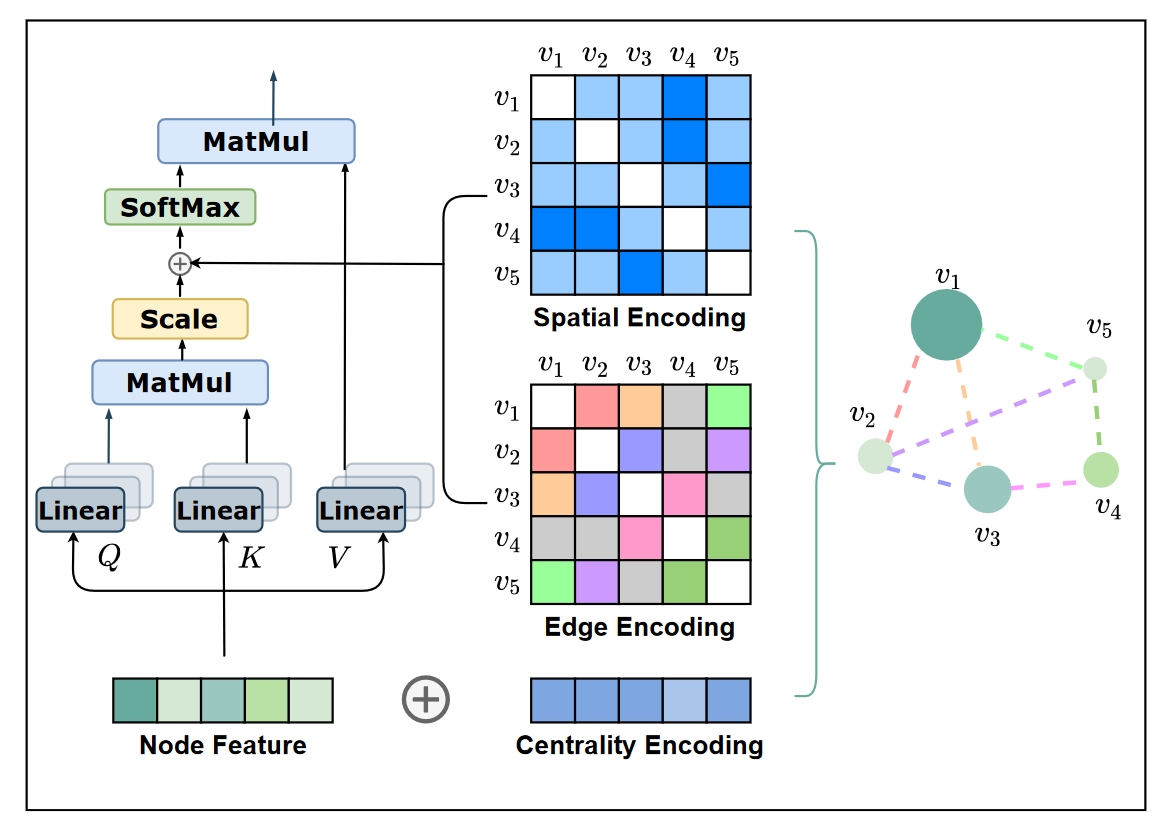
# Centrality Encoding
To capture the importance of nodes within the graph, the authors use degree centrality as an additional signal. Each node is assigned two real-valued embedding vectors based on its indegree and outdegree, which are added to the node features.
# Spatial Encoding
To model the structural relations between nodes, the authors introduce a spatial encoding that uses the shortest path distance (SPD) between nodes as a learnable bias term in the softmax attention mechanism. This allows the model to adaptively attend to nodes based on their spatial proximity.
# Edge Encoding
The authors propose a new method to encode edge features by computing the average of dot-products of edge features and learnable embeddings along the shortest path between nodes. This edge encoding is incorporated as a bias term in the attention module, enhancing the model's ability to capture spatial dependencies.
The paper demonstrates that Graphormer achieves state-of-the-art performance on a wide range of graph-level prediction tasks, including the Open Graph Benchmark Large-Scale Challenge (OGB-LSC) and other popular leaderboards. The authors also mathematically show that Graphormer's expressive power covers many popular GNN variants as special cases, highlighting its versatility and adaptability.
The authors conduct experiments on quantum chemistry regression datasets and other graph representation tasks, consistently outperforming previous state-of-the-art GNNs. They also perform ablation studies to validate the importance of the proposed structural encodings.
In conclusion, Graphormer represents a significant advancement in applying Transformer architectures to graph representation learning, showing promising results in various benchmark tasks. The paper leaves open avenues for future work, such as improving the efficiency of Graphormer for large graphs, exploring different centrality measures and spatial encoding functions, and developing graph sampling strategies for node representation extraction.