
# Graph Data Augmentation
# Overview
In recent years, data-driven reasoning has significantly improved its generalization ability and model performance with the introduction of data augmentation technology. Data augmentation technology increases the amount of training data by creating reasonable variations of existing data without the need for additional real labels, and has been widely applied in computer vision (CV) and natural language processing (NLP).
With the rapid development of graph machine learning methods such as graph neural networks, people's interest and demand for graph data augmentation (GDA) technology continue to increase. However, due to the irregular and non Euclidean structure of graph data, it is difficult to directly apply the data augmentation technique (DA) used in CV and NLP to the field of graph.
In addition, graph machine learning faces unique challenges, such as:
- Incomplete feature data
- Sparsity of Structural Data Caused by Power Law Distribution.
- Lack of labeled data due to the high cost of manual annotation.
- Excessive smoothing caused by message passing in GNN.
In order to address these challenges, there are increasing works on graph data augmentation. Similar to data augmentation techniques such as CV and NLP, graph data augmentation creates data objects through modification or generation. However, due to the fact that graphs are connected data, unlike images and text, the data objects in graph machine learning are usually non independent and identically distributed. Therefore, whether it is node level, edge level, or graph level tasks, graph data augmentation techniques often make changes to the entire graph dataset.
Base on this,GraphCL(NIPS 2020)provided four most commonly used augmentation strategies,namely:
- Node dropping,
- Edge perturbation
- Attribute masking
- Subgraph sampling
Although the above attempts to apply data augmentation to Graphs often fail to generate views on the semantics of the original graph or adapt augmentation strategies to specific graph learning tasks.
# Mixup Method
Mixup[1] is a simple data augmentation method proposed in ICLR2017 used in computer vision. It improves model's generaliztion power as well as robust to adversarial attack by perform linear transformation on input data.
Basic mixup method use formula as below:
It's applications are usually used for these four motivation.
# Model normalization
- AdaMixup founded that hybrid samples may be conflict with other real samples when we conduct Mixup, as shown in the following figure:
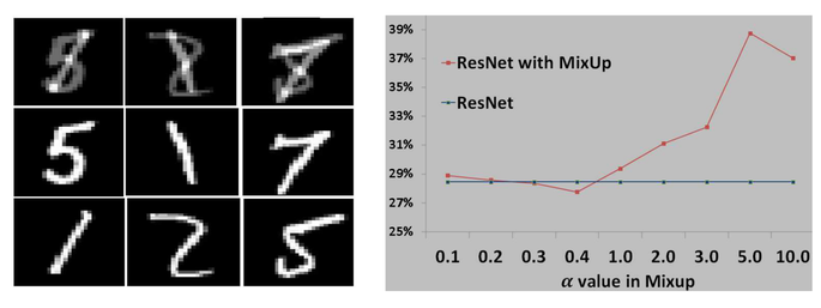
They proposed a model to classify whether samples come from hybrid or real sample.
CutMix cut a part of image to merge two image in a smoother and more continues way. However this may cut the background of an image, which doesn't make contributions to features but do harm to label prediction.
Patup fix CutMix's weakness, they do mix-up in high-dimension. And PuzzleMix mix different part with a hign information density in each images.
# Semi-supervised method
Mixup method can generation pseudo labels with high quality by mixing up labeled and unlabeled images and other labeled image as training set. ICT first launched a semi-supervised method by utilizing consistent loss. Consistency regularization is another commonly used operation in semi supervised learning, in addition to pseudo labels. It assumes that if we perturb the input to a certain extent, the model predictions should be similar.
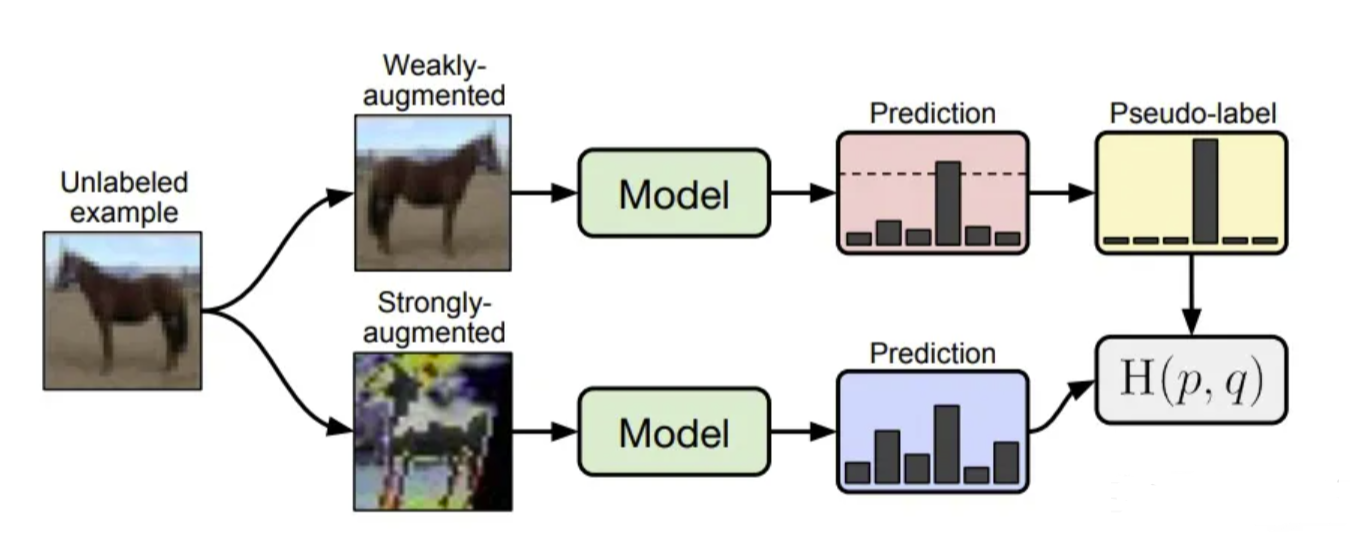 Here strong or weak augmentation often include three aspects:
Here strong or weak augmentation often include three aspects:
- Data augmentation
- Adversarial training
- Transformation, e.g., automatic exposure, brightness, color, contrast, sharpness, equalization, posterize, overexposure, rotate, translate
# Domain Adaptation
Domain Adaptation can be seen as cross-domain semi-supervised learning where the source domain is labeled and the target domain is unlabeled. Based on this approach, Mixup can provide high-quality pseudo labels for the target domain. The existing usage methods include:
Adversarial training + domain sample Mixup, such as Dual Mixup and Virtual Mixup, treats Mixup as a regularization method to enhance the diversity of features learned by the model
When using intra domain and inter domain mixups in combination, multiple methods are used to obtain sample pseudo labels for unlabeled target domains. The prediction target of the model is obtained through the mixture of pseudo labels and true labels. The acquisition of pseudo labels is the key to the success of these methods.
Use collaborative training similar to Teacher Student to train multiple classifiers, and then mix the provided labels with samples with real labels to provide pseudo labels for Mixup. The main function played by Mixup here is to reduce the noise of pseudo labels.
# Generation
Manifold Mixup pointed out that Mixup can be used to regularize GAN. Note that this mixing must be cross domain, that is, mixing Fake to Fake and Fake to Real. However, in the Real Image domain, such as Real to Real mixing, mixing can actually reduce the generation effect of the model. In fact, the mixed image produced by Real to Real is not a Real Image, which is also worth studying. However, in summary, this mixing is meaningful for improving the generation model.
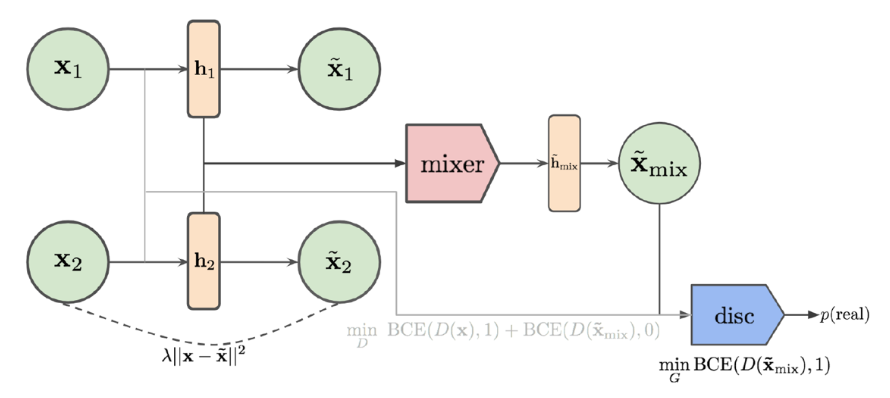
In addition, Mixup can also be used for training VAE and GAN hybrid generation models, as shown in the following figure. The entire generation model consists of an autoencoder and a discriminator. Among them, the autoencoder maps the input to the feature space and maps it back to the original space through the decoder, using classical reconstruction loss for training, requiring the distance between the pre and post mapping to be as close as possible. The discriminator tries to distinguish the features before and after the mapping, usually trained with a binary loss function. In addition, it is also required that the generated results of the autoencoder can confuse the discriminator. Because autoencoder is generated one-on-one, in order to maximize the discriminator's ability to utilize as many samples as possible.
By fusing in the feature space, mixed features can be obtained in the feature space , and then map back to in the original space.
# G-Mixup
Title: G-Mixup: Graph Data Augmentation for Graph Classification.
This paper proposed a Mix-up method for graph-level classification. It first generates graphons from different graphs. The dimension of graphon is valued as average node numbers of each graph, and then generate graphs by mix-uped graphons with mix-uped label as well. The mixup-ed sample is fed to model thus improving robustness of model.
# GCL
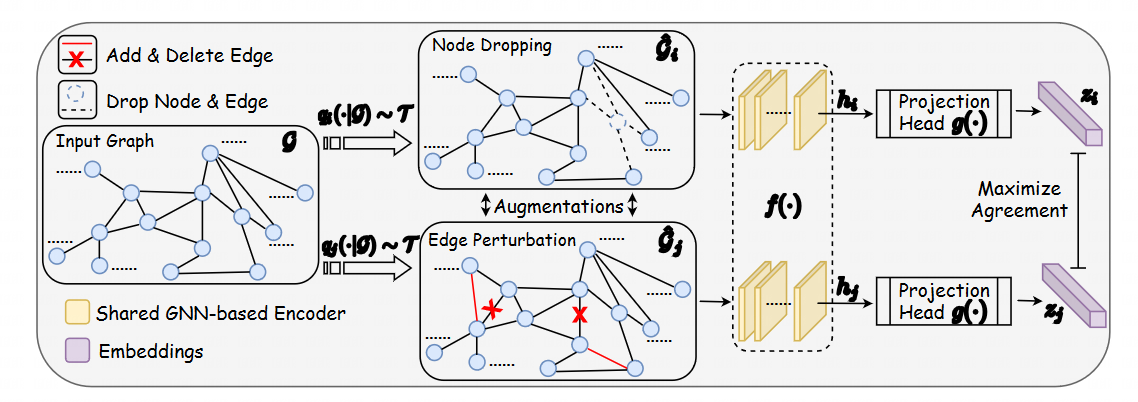
Title: Graph Contrastive Learning with Augmentations.
This paper Introduces 4 basic methods for graph data augmentation.

This paper demonstrates the feasibility of four different approaches through experiments and the outcomes of their combined use. The experiments reveal that for social networks and molecular graphs, distinct data augmentation and contrastive learning strategies should be employed to achieve better results; otherwise, the opposite effect may occur. For instance, in the recognition of benzene ring structures, breaking chemical bonds and treating them as positive samples can lead to a deterioration in the effectiveness of contrastive learning.
# DGCL/AutoGCL
DGCL considers two graph corruptions: removing edges for topology and masking features for node attributes for a node, and generate this node's embedding in different views (parameters weight matrix), aimming to minimize the distance between node embedding in different views. One of the most important contribution of DGCL is proving the low boundary of its MI (Mutual Information) is not more than InfoNCE loss.
AutoGCL considers all previous graph data augmentation strategies and uses a sharpened softmax to enable the model to autonomously learn which augmentation strategy to employ. The paper employs two graph view networks, with each sample being processed separately through these two networks, and the loss derived from the two views is minimized.
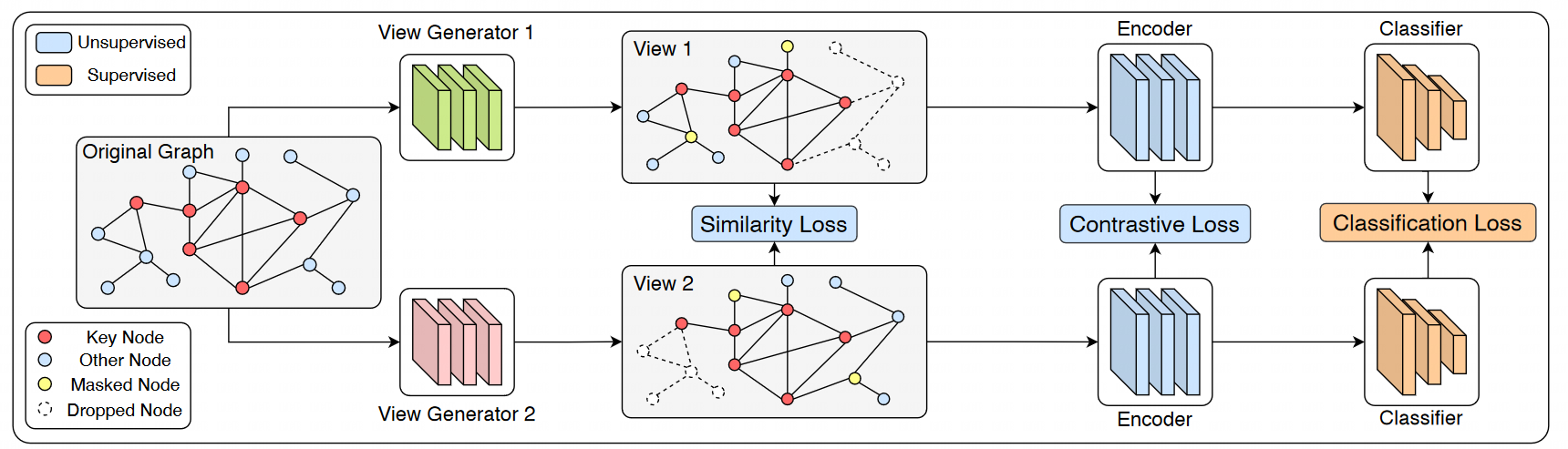
Furthermore, the paper also points out that excessive use of contrastive learning during the pre-training process may potentially impact the model's effectiveness. This is because relying solely on the intrinsic features for feature modeling can easily lead to learning all samples near the decision boundary, thereby affecting the performance of subsequent classifiers.
# MEGA
The core idea of this paper is to introduce an LGA (Learned Groupwise Aggregation) module, which is responsible for minimizing redundancy in the features learned by the contrastive learning encoder. In other words, it aims to make these representations as dissimilar as possible. This process may potentially undermine the effectiveness of contrastive learning, so another round of contrastive learning will be performed afterward. The model will iterate through this process until the desired optimal performance is achieved.