# Graph Pre-train
In the past few years, graph representation learning and Graph Neural Networks (GNN) have become a popular research area for analyzing graph-structured data. Graph representation learning aims to transform graph data with complex structures into dense representations in a low-dimensional space that retain diverse graph attributes and structural features. Typically, GNN takes graphs with attributes as input and uses convolutional layers to generate node-level representations layer by layer. For a specific task on the input graph, GNN models are trained in an end-to-end manner using supervised information. In other words, for different tasks on the same graph, you would need datasets with sufficient and distinct labels to train specific GNNs for each task. However, acquiring labels for these tasks, especially for large-scale graph data, can be costly and challenging to obtain a substantial amount of annotated data.
One effective way to address this problem is to pretrain GNN models in a self-supervised manner on unlabeled data. This way, only a small amount of labeled data is required for fine-tuning the model on downstream tasks.
# Strategies
This article introduces a novel GNN pretraining strategy and self-supervised method. However, improvements from pretraining the GNN on the entire graph or individual nodes alone are limited, and it can even lead to negative transfer on some downstream tasks. Therefore, this paper performs pretraining on both individual nodes and the entire graph, allowing the GNN to simultaneously learn local and global information propagation. The authors propose two node-level self-supervised learning methods. In the context prediction task, the model is trained to predict the surrounding graph structure through subgraph prediction, enabling the model to predict the surrounding structure based on the central node. In the attribute masking task, the network learns to predict masked nodes or edges, allowing it to learn graph properties and domain knowledge.

After node-level pretraining, graph-level pretraining is conducted. To encode domain-specific information into graph representations, the authors propose a graph-level multi-task supervised pretraining. This involves jointly predicting labels for multiple graphs, with each attribute corresponding to a binary classification task. After obtaining graph representations, linear classifiers are used for classification.
Following pretraining, the obtained GNN model is fine-tuned on downstream tasks. Graph-level representations are used to predict downstream task labels after passing through a linear classifier. As shown in the table below, this pretraining framework outperforms the state-of-the-art in molecular property prediction and protein function prediction tasks.
# GPT-GNN
The GPT-GNN proposed in this article initializes the GNN using a generative pretraining approach, and the following figure illustrates the pretraining-fine-tuning process of GPT-GNN.
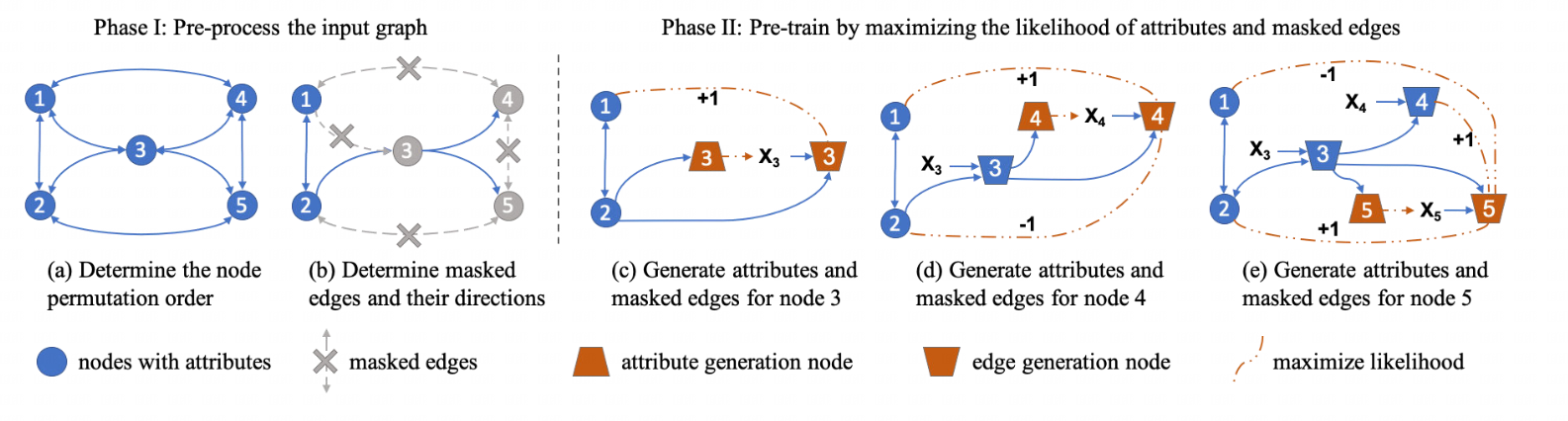
As shown in the figure above, GNN is first pretrained by reconstructing/generating the structural information and node attribute information of the input graph. Subsequently, the pretrained GNN and its parameters are used for downstream tasks, where it is fine-tuned with a small amount of annotated data.
During the pretraining process, for the sake of training efficiency, the authors aim to calculate the losses for both node attribute generation and edge generation processes in a single pass of GNN on the input graph. However, the generation of edges relies on node attribute information, and simultaneously conducting both generation processes could lead to information leakage. To address this issue, the article categorizes nodes into two types, attribute generation nodes and edge generation nodes, at different stages. It is worth noting that the same node can function as both an attribute generation node and an edge generation node at different stages.
The authors provide a specific example of the attribute graph generation process. The first part involves preprocessing the input graph: determining the ordering of nodes in the input graph, randomly selecting a subset of edges connected to the target node as observed edges, and marking the remaining edges as masked edges, which are then removed. The second part is the pretraining process: nodes are categorized as attribute generation nodes or edge generation nodes, and the representations of nodes 3, 4, and 5 are computed, including their attribute generation nodes and edge generation nodes. Finally, the GNN model is trained by parallelizing node attribute prediction and masked edge prediction for each node.
# GCC
Paper title: GCC: Graph Contrastive Coding for Graph Neural Network Pre-Training
This paper employed contrastive learning and pre-training paradigms in graph learning.
The core idea is to use a subgraph sample of a single node with anonymous, restartable, random walks as q, and samples on the current graph and on other graphs as k to compute an InfoNSE loss. The encoders for q and k are implemented using two different neural networks. Subsequently, this encoder is tested for downstream task performance.
However, it's important to note that having a large number of k can consume significant storage and computational resources. The paper proposes two solutions: the first is to reduce the size of k using minibatch, and the second is to update only the parameters of q and use them to progressively update k. In other words, only q is updated using backpropagation, and k is updated using q.
Additionally, the paper presents two different training strategies, namely freezing parameters and fine-tuning mode.
# When to and when not to train.
Paper title: When to Pre-Train Graph Neural Networks? From Data Generation Perspective!
The paper discusses from the perspective of Graphons when pretraining is necessary and when it is not. In other words, when the Graphon of the pretrained graph is similar to the Graphon of the target graph, pretraining will yield positive results, whereas it may be detrimental to downstream tasks when they are dissimilar. Generally speaking, knowledge is not readily transferable between different networks. A typical example is that a triangular structure represents instability in molecules, while in social networks, it often signifies stability.
# Pretrain and Meta-learning